


What do Covid, enrolment at Berkeley and kidney stone treatments have in common?

Understanding data goes beyond merely loading it into Excel or visualising it in Tableau. It involves comprehending correlation, causation and drivers, as well as interpreting it accurately.
Data interpretation implies grasping any trend or effect of specific drivers. In medicine, data is frequently employed to understand the impact of certain treatments on curing particular ailments. Let's consider a large pharmaceutical company studying the effect of two drugs on the treatment of a particular disease. The company discovers that drug B boasts an 83% success rate in treating the disease (289/350), while drug A has a success rate of 78% (273/350). Clearly, the company would advocate for drug B as it seems to exhibit a higher success rate. However, suppose a savvy analyst decides to delve deeper and divides the population into those with a mild version of the disease and those with a severe case.
The analyst uncovers that:
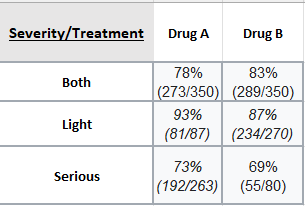
What this reveals is that drug A had a lower success rate because it was administered to a majority of severe cases, while drug B was primarily used in milder and less serious cases. In fact, drug A was more effective in curing the disease both for milder and more serious cases.
This example is derived from a well known real-life medical study on kidney stone treatment and it is not an isolated case.
At the onset of the COVID pandemic, many people wondered why COVID cases resulted in such high mortality in Italy compared to China. It was, in fact, another instance of the so-called Simpson’s paradox, wherein a variable appears to have a higher effect on the entire population but, when compared across several subsets, it actually has a lower impact. Researchers found that COVID mortality was lower in Italy for every age group compared to China, but a higher percentage of older people in Italy were contracting the disease, skewing the general results and creating the illusion of a higher percentage of people dying from the disease.
From Berkeley’s apparent gender bias to batting average (where one player can have a higher batting average than another player each year for several years but a lower batting average across all those years), Simpson's paradox awaits many an inexperienced data scientist who fail to understand the distribution in their data.
Many causal effects do not act uniformly on the data (medicines may treat milder forms of the disease better than more serious ones, older people may experience more serious consequences from contracting an ailment, and so on). Therefore, the distribution of the data becomes an important factor to consider. It is in these cases that Simpson's paradox may manifest itself.
If people's happiness increases with wealth in every country, but wealthier people happen to reside in countries where people are less content in general, one may mistakenly conclude that wealth does not bring happiness. In reality, there may be other confounding factors making people in certain countries less content apart from wealth, for example food or the weather.
In addition to confounding variables, reverse causation may also play a role in Simpson's paradox, leading to the absurd conclusion that medicine kills because people who take more medicines are more likely to die. In fact, people who take medicines are more likely to survive any disease; however, individuals who take many medicines are often sicker and older. If we compared the same group of people, we would see that those who take medicines generally heal faster and better than those who do not. However, when looking at the entire population, one may naively conclude that more people die among those who take more medicines.
The Simpson's paradox serves as a poignant reminder that superficial interpretations can be misleading and the devil often lies in the details of data distribution. Recognising that causation may not act uniformly and acknowledging the impact of confounding variables ensures a more accurate interpretation of the data landscape. Like the Zeno’s paradox can be easily overcome with a simple understanding of limits and infinitesimals in Mathematics, similarly, the Simpson’s paradox is a paradox only for those who do not understand data distribution.
The Simpson's paradox cannot occur if the distributions are the same across subgroups. For Simpson's reversal to emerge, there must be heterogeneous distributions of the relevant causal and confounding variables in the different subgroups. Homogeneous distributions mean the subgroup trends will remain consistent at the aggregate level, preventing any paradoxical association flip.
The different underlying data distributions are an essential ingredient for the Simpson's paradox and without distributional differences in subgroups, the paradox cannot manifest.
Heads up, there's a mix-up in the stats about the drugs. Drug A actually has a higher success rate (83%) compared to drug B (78%). The text mistakenly says it's the other way around. Just a quick fix needed I think!